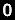
Ciò che gli amici scrivono su Twitter rivela una quantità sorprendente di informazioni su di noi.
Alcune aziende fanno miliardi trasformando tutto ciò che diciamo, facciamo e guardiamo online attraverso la profilazione degli utenti e dei consumatori. Recentemente, alcuni utenti hanno deciso di limitare l’uso dei social media e alcuni di eliminare completamente i loro account.
Secondo un recente studio, purtroppo neppure queste strategie sono sufficienti a garantire la privacy. Basta infatti essere collegato ad altri utenti, perchè le loro attività espongano anche chi è collegato con loro. Scienziati informatici hanno, infatti, dimostrato che i flussi Twitter dei 10 contatti più vicini sono sufficienti a prevedere quelli che sarebbero i nostri possibili tweet.
È molto più facile di quanto sembri. Questa sorveglianza di seconda mano è sufficiente a capire il carattere di una persona dice David Garcia, scienziato sociale computazionale presso l’Università di Medicina di Vienna in Austria.
Invece di prevedere i tweet di qualcuno, i ricercatori dell’Università del Vermont, di Burlington, hanno stimato quanto prevedibili sarebbero state le possibili parole usate da una persona, selezionandole attraverso una metodologia entropica/casualità, secondo la quale più c’è entropia/più casualità e meno ci saranno ripetizioni. Sono stati esaminati i flussi Twitter di 927 utenti, ognuno dei quali aveva da 50 a 500 follower, e altrettanti 15 utenti, per ciascuno di loro, che avevano prodotto il massimo dei twitt . Nel flusso di ogni individuo, è stata quindi calcolata la quantità di entropia contenuta nelle sequenze di parole.
Il numero ottenuto è stato inserito in uno strumento, preso dalla teoria dell’informazione, chiamato “Disuguaglianza di Fano” che calcola il fattore predittivo di una parola come possibile prossimo tweet nel flusso di una persona. Il fattore medio massimo è del 53%.
Successivamente, è stato calcolato il limite massimo superiore e la previsione è salita al 60%. Quando è stato rimosso il flusso dell’utente dall’equazione, la cifra è scesa a circa il 57%. Ciò significa che osservare i flussi dei contatti di un utente è quasi altrettanto valido che includere l’utente, e anche meglio di sorvegliare l’utente da solo. Ci sono voluti i flussi di 10 soli contatti per ottenere una precisione predittiva superiore a quella del proprio flusso Twitter individuale. Se si fa un confronto, la previsione di ciò che qualcuno scriverà, basandosi su un assortimento casuale di tweet di estranei, restituisce una precisione massima del 51%. (Questa è quasi uguale alla prevedibilità dei tweet che la persona stessa potrebbe generare, perché la regolarità nella lingua inglese di ciò di cui parlano le persone è molto alta, circa il 53%).
"Dedurre le dimensioni dell'universo causale:
caratteristiche e fusione delle reti di attribuzione causale"
Nuovo lavoro che esplora le strutture dell'inferenza umana
da@bagrow w/ studente Daniel Berenberg
Usando alcune formule matematiche della teoria dell’informazione, James Bagrow, autore principale dello studio, si domanda: “Ma se si disponesse di un metodo di apprendimento automatico perfetto, quanto ci si potrebbe fare?”
E Joanne Hinds, psicologa dell’Università di Bath nel Regno Unito, aggiunge “Si tratta di un metodo unico, che va ben oltre la maggior parte del lavoro esistente in questo settore”.
I risultati mostrano che, in linea di principio, si potrebbe approssimativamente prevedere cosa twitterebbe qualcuno che non è nemmeno su Twitter. Ciò permetterebbe di scoprire chi erano gli amici offline di una persona e poi riuscire a trovare i feed di quegli amici su Twitter. Molte app richiedono l’accesso agli elenchi dei propri contatti e la tendenza maggiore è quella di condividerli e per quelli che non li condividono ci pensa Facebook che ha gli elenchi delle liste di contatti degli utenti che non ne autorizzano la visibilità, anche di quelli legati a “profili ombra” di persone che non si trovano nemmeno sulla rete.
I ricercatori hanno già usato i tweet delle persone per prevedere: personalità, grado di depressione e orientamento politico. Allo stesso modo i tweet ipotetici, prevedibili a partire dai tweet degli amici potrebbero consentire di ottenere informazioni dello stesso tipo.
Una limitazione pratica di questo studio è che tratta tutte le parole con un grado informativo uguale, ma alcune potrebbero raccontare di più rispetto ad altre. Se i tuoi amici twittano molto su, ad esempio, i diritti degli omosessuali o seguono solo politici repubblicani, ciò potrebbe rivelare in modo specifico il tuo orientamento sessuale o quello politico. “Abbiamo appena scalfito la superficie di quali tipi di informazioni possono essere emerse in questo modo”, afferma Hinds.
“Quello che mi preoccupa in termini di privacy”, afferma Bagrow, “sono i moltissimi modi attarverso i quali le grandi piattaforme in rete stanno acquisendo dati, e ancor di più che la gente non non se ne rende conto”.
Linkografia: